Projects from the FLAME Center
The following are projects relating to foundation models carried out by one or more of the FLAME center faculty. This list is not exhaustive, and more information will be available on their respective web pages.

Machine Learning Compilation for Large Language Models
Machine Learning Compilation for Large Language Models (MLC LLM) is a universal solution that allows any language model to be deployed natively on a diverse set of hardware backends and native applications.

LLM Attacks
LLMs undergo extensive fine-tuning to not produce harmful content. LLM Attacks is a proof-of-concept that demonstrates that it is possible to construct adversarial attacks on LLMs in an automated fashion that can bypass this fine-tuning process, with security implementations.
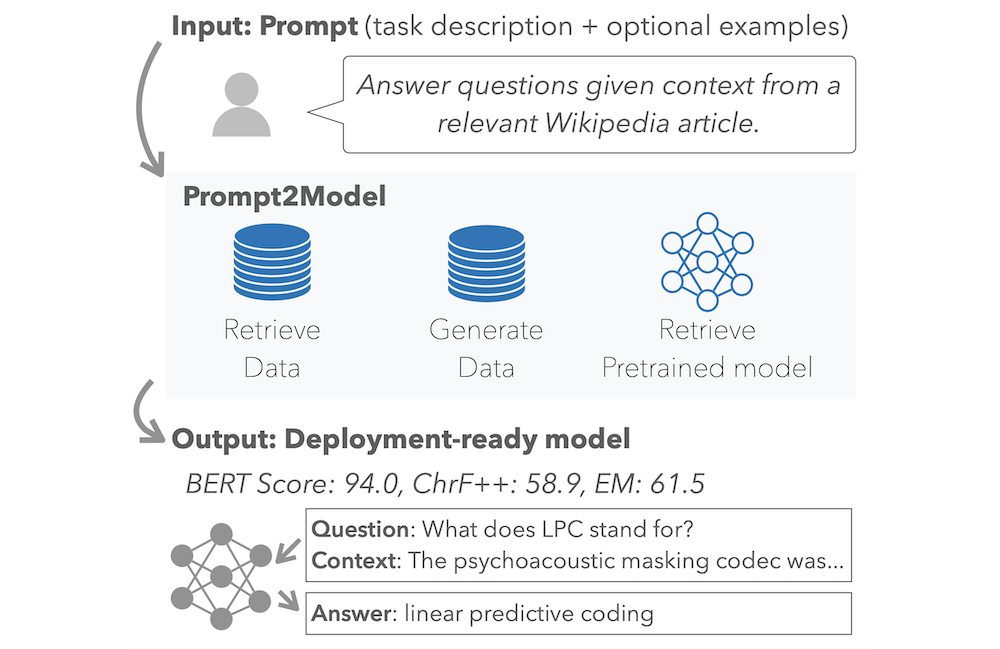
Prompt2Model - Generate Deployable Models from Instructions
Prompt2Model is a system that takes a natural language task description (like the prompts used for LLMs such as ChatGPT) to train a small special-purpose model that is conducive for deployment.
FlexFlow Serve: Low-Latency, High-Performance LLM Serving
FlexFlow Serve is an open-source compiler and distributed system for low latency, high performance LLM serving. FlexFlow Serve outperforms existing systems by 1.3-2.0x for single-node, multi-GPU inference and by 1.4-2.4x for multi-node, multi-GPU inference
Zeno: AI Evaluation Made Easy
Zeno is an interactive AI evaluation platform for exploring, discovering and reporting the performance of your models. Use it for any task and data type with Zeno's modular views for everything from object detection to audio transcription and chatbot conversations. Zeno helps you move beyond aggregate metrics and spot-checking model outputs to develop a deep and quantitative understanding of how your model behaves.
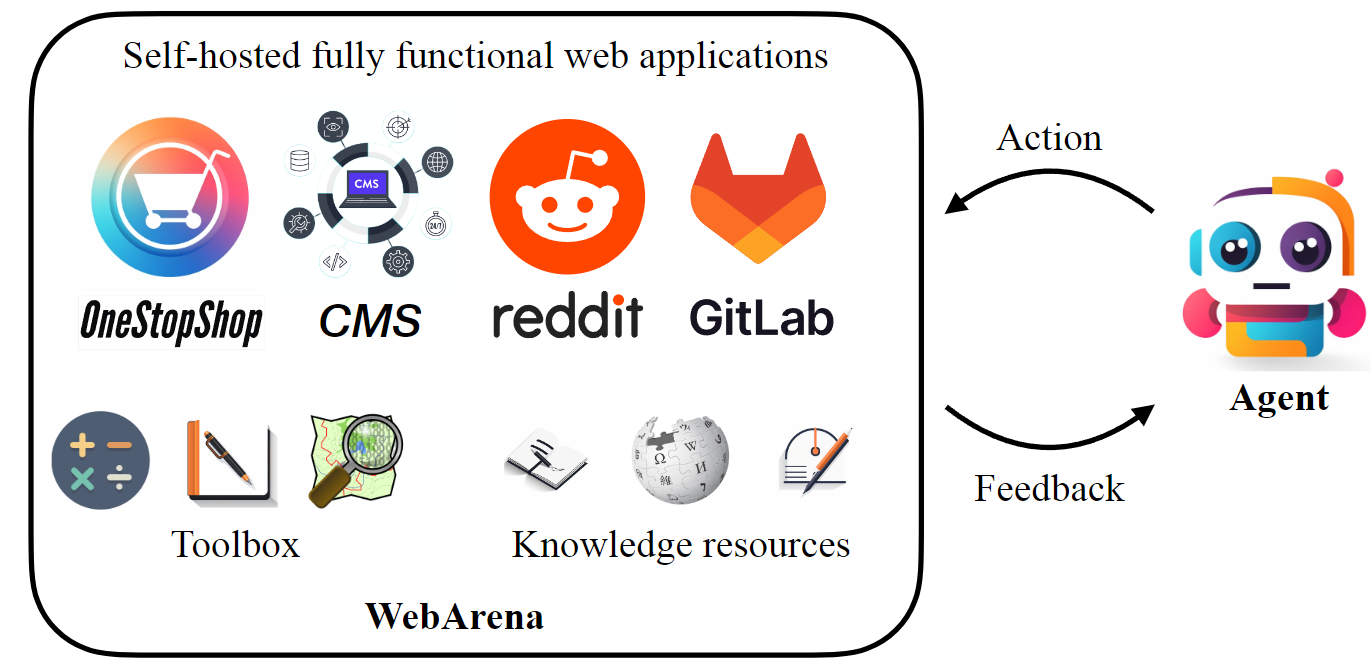
WebArena: A Realistic Web Environment for Building Autonomous Agents
WebArena is a standalone, self-hostable web environment for building autonomous agents. WebArena creates websites from four popular categories with functionality and data mimicking their real-world equivalents. This is accompanied by a benchmark on interpreting high-level realistic natural language command to concrete web-based interactions.
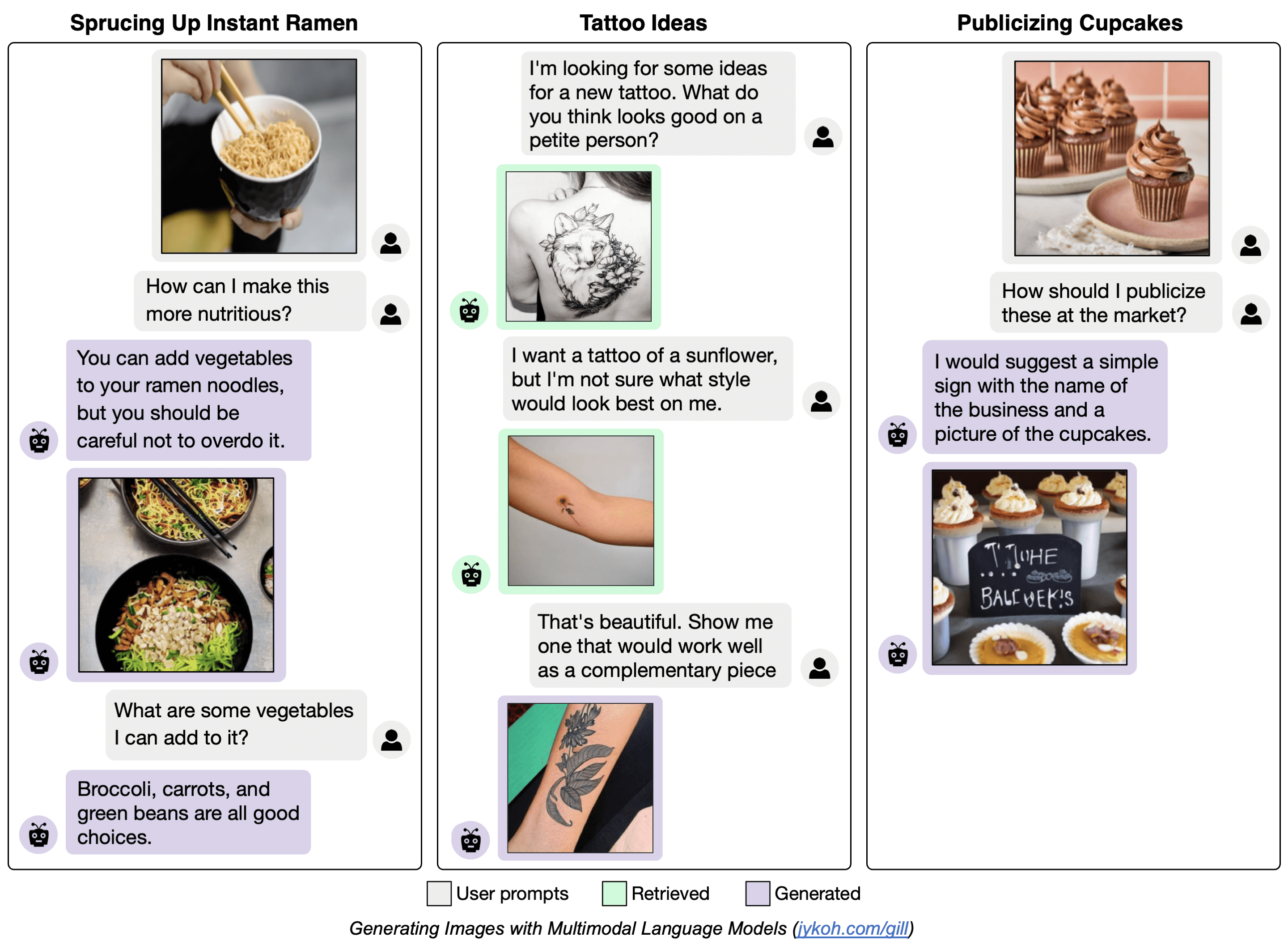
Generating Images with Large Language Models (GILL)
GILL is capable of processing arbitrarily interleaved image-and-text inputs to generate text, retrieve images, and generate novel images. GILL is the first approach capable of conditioning on arbitrarily interleaved image and text inputs to generate coherent image (and text) outputs.
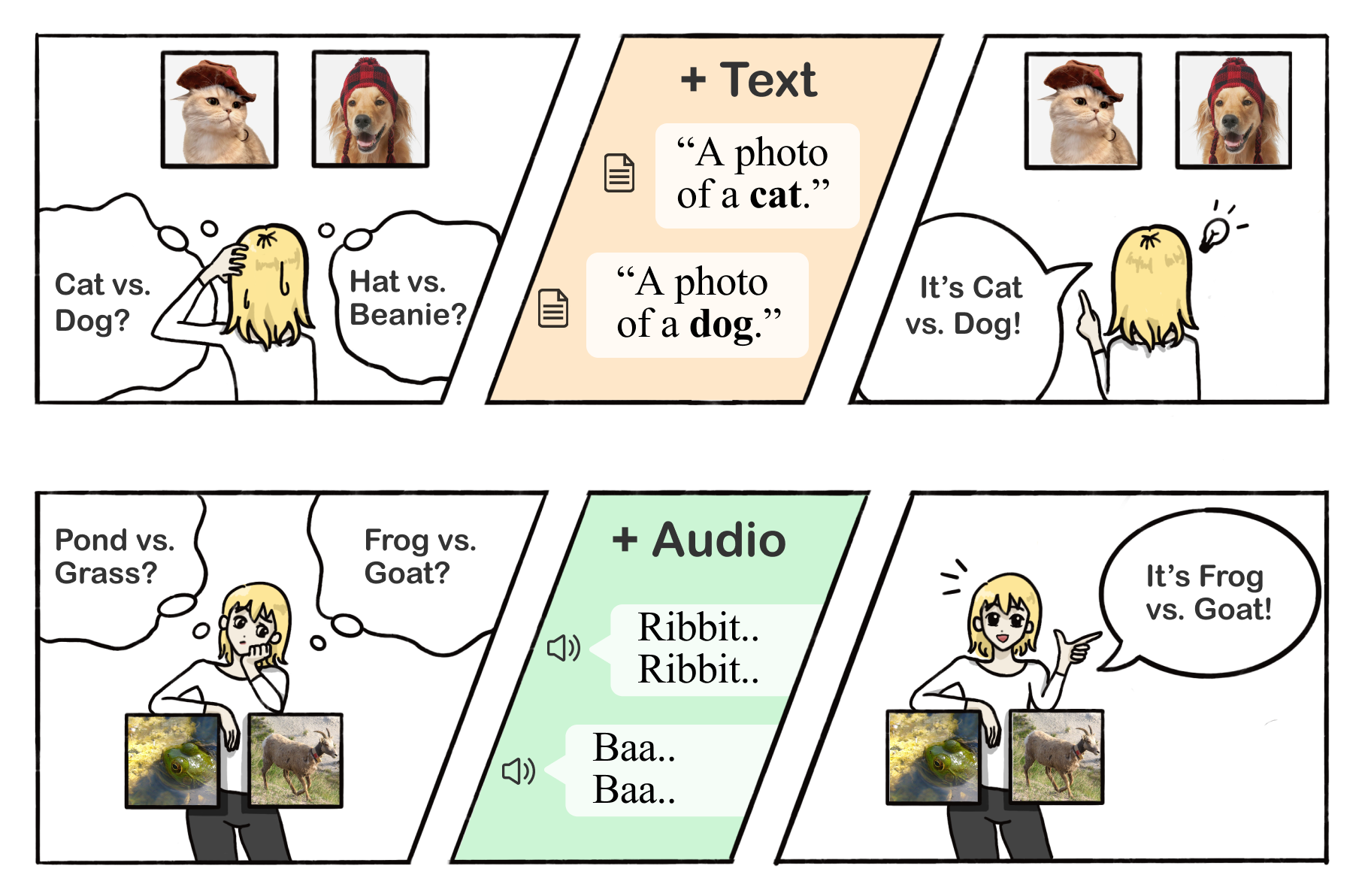
Cross-modal few-shot adaptation with CLIP
A simple cross-modal adaptation approach that learns from few-shot examples spanning different modalities. We demonstrate that one can indeed build a better visual dog classifier by reading about dogs and listening to them bark. To do so, we exploit the fact that recent multimodal foundation models such as CLIP are inherently cross-modal, mapping different modalities to the same representation space.

Sotopia: an Open-ended Social Learning Environment
Sotopia is an open-ended environment to simulate complex social interactions between LLM-based artificial agents and evaluate their social intelligence. Agents role-play and interact under a wide variety of scenarios to achieve complex social goals.
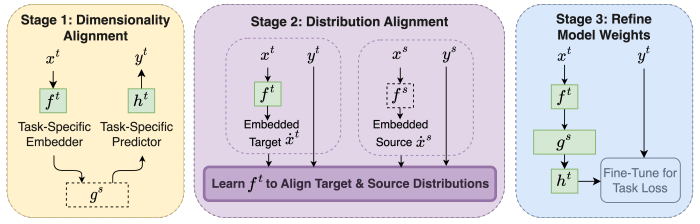
ORCA: Cross-Modal Fine-Tuning
ORCA is a general cross-modal fine-tuning framework that extends the applicability of a single large-scale pretrained model to diverse modalities. ORCA adapts to a target task via an align-then-refine workflow: given the target input, ORCA first learns an embedding network that aligns the embedded feature distribution with the pretraining modality. The pretrained model is then fine-tuned on the embedded data to exploit the knowledge shared across modalities. ORCA obtains state-of-the-art results on 3 benchmarks containing over 60 datasets from 12 modalities.
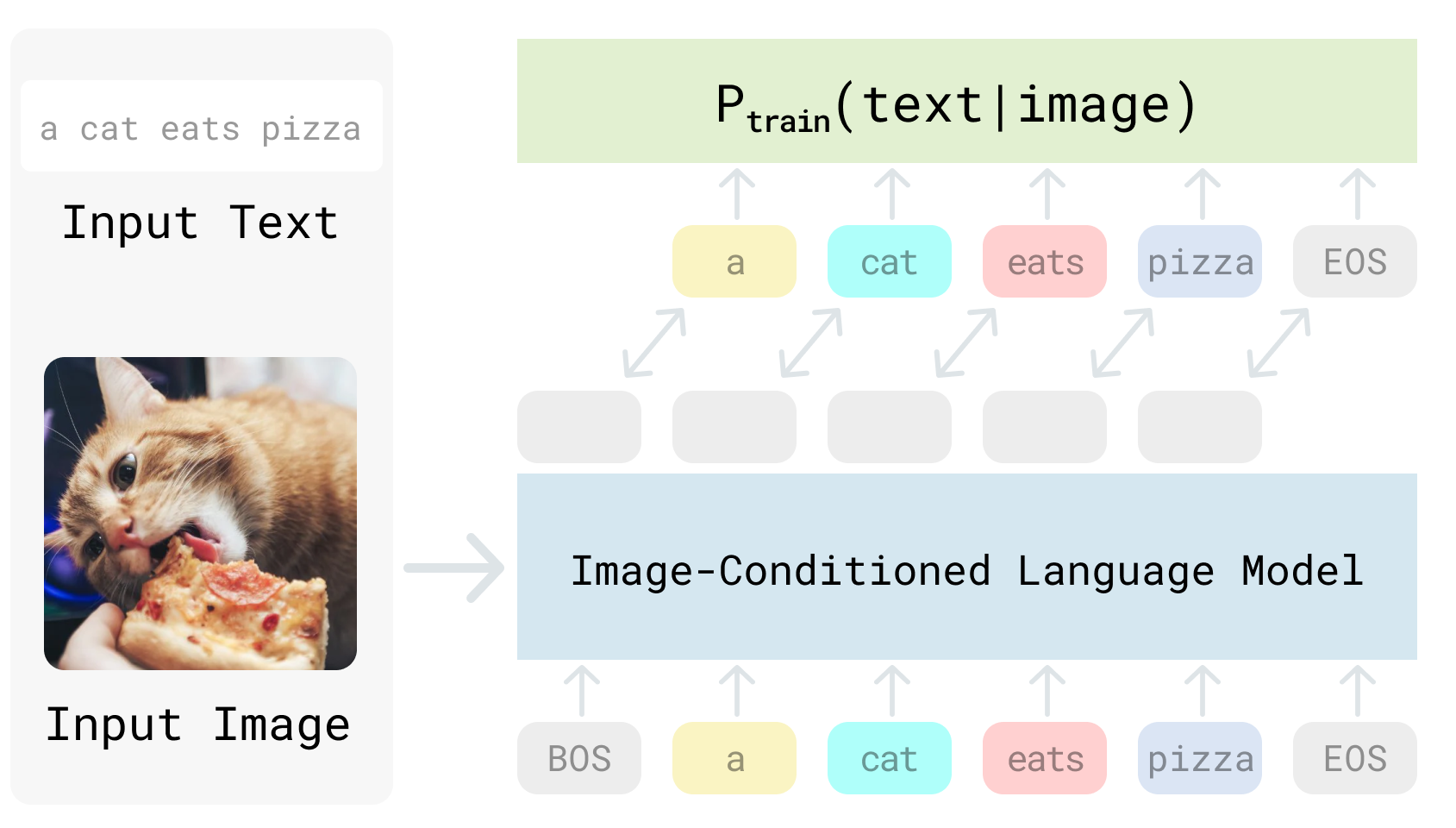
Visual Generative Pre-Training Score (VisualGPTScore)
We study generative Vision-language models (VLMs) that are trained for next-word generation given an image. We explore their zero-shot performance on the illustrative task of image-text retrieval. We observe that they can be repurposed for discriminative tasks (such as image-text retrieval) by simply computing VisualGPTScore, the match score of generating a particular text string given an image.